Anthropic shipped two models this morning, and the headline practically writes itself: Claude Fable 5 is now the most capable model the company has ever made generally available, topping nearly every benchmark anyone has bothered to run it through. Its sibling, Mythos 5, is the same model with some of its safety restraints removed, reserved for cyberdefenders and a small circle of trusted partners.
So yes, the leaderboard moved. Again. If you've worked in this field longer than a single news cycle, you've learned to greet "state-of-the-art on nearly all benchmarks" with a polite nod and a slightly raised eyebrow.
But I build AI agents and evaluation frameworks for a living, and the line that made me put my coffee down wasn't a benchmark at all. It was this: the longer and more complex the task, the larger Fable's lead grows.
That sentence should matter to anyone shipping agents.
Same brain, two names
First, the naming — because it's the quietly clever bit. Fable and Mythos are the same underlying model. The only difference is the leash. Fable politely tags out to its sturdy older sibling, Opus 4.8, when a request wanders into sensitive territory; Mythos keeps going. Fable comes from the Latin for "that which is told," and Mythos is its Greek cousin. Same story — told to two very different audiences, one of which is allowed to stay out past curfew.
It's a tidy bit of product philosophy disguised as a Latin lesson: capability and safety aren't two separate models, they're the same engine with different governors installed.
Stamina, not just smarts
For years, the real ceiling on agentic systems hasn't been intelligence-per-token. It's been stamina. Agents drift. They lose the thread somewhere around step 40, confidently forget what they were doing, and cheerfully optimize for the wrong subgoal. Most of us have built more scaffolding to keep a model on task than to make it smart in the first place — elaborate Rube Goldberg machines whose entire job was reminding the model what it was doing ten seconds ago.
A model that gets relatively better as the task gets longer is a different category of tool. The shift worth internalizing isn't "it scored higher." It's "the gap between it and everything before it grows precisely where real work lives: long, messy, multi-step, autonomous."
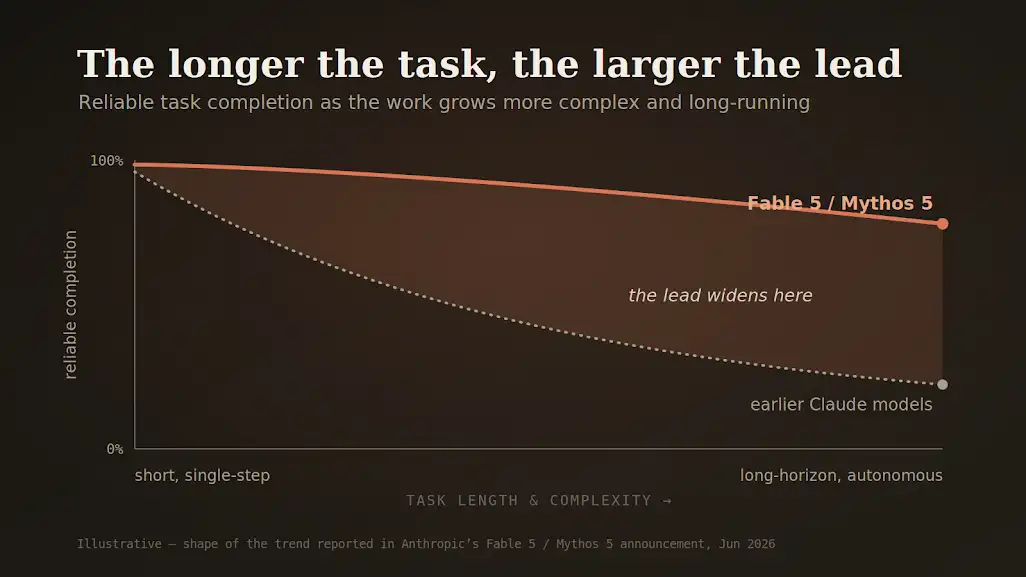
The frontier isn't a single number. The advantage compounds as tasks get longer and more complex — exactly where agents have historically fallen apart.
The receipts back it up:
- Stripe reportedly ran a codebase-wide migration across 50 million lines of Ruby in a day — work it estimated at over two months by hand.
- Give it persistent, file-based memory and it improved at a deck-building game roughly three times more than Opus did with the same crutch — learning from its own notes as it went.
- It beat Pokémon FireRed on raw screenshots alone — no map, no walkthrough, no strategy guide bought with lawn-mowing money. It made it through Rock Tunnel without Flash, in the pitch dark, which is more than I managed at age ten. Earlier models needed a GPS, a Sherpa, and an emotional support harness just to find their way out of Pallet Town.
- Filed firmly under we-live-in-the-future: it composed a classical-EDM remix entirely in code, having never heard a single note of music. Somewhere, a producer with a $4,000 audio interface is quietly updating his résumé.
If your agent's signature failure mode is "loses the plot on a long-horizon task," this is the release to read closely.
The potential isn't in the coding demos. It's in the lab.
Coding headlines get the clicks, but the results that should make you sit up are in the sciences — because that's where "an agent that can stay focused for a week" stops being a productivity feature and starts being a research collaborator.
Using Mythos 5, Anthropic's own protein-design experts report accelerating parts of the drug-design process by roughly ten times — with the model choosing binding sites, running design tools, and recovering from its own failures, largely unattended. In blinded head-to-head reviews, scientists preferred Mythos's molecular-biology hypotheses about 80% of the time over Opus-class models, and have advanced several toward experimental validation. In one case, a hypothesis the model generated was independently corroborated by a separate lab working the same problem.

A sample of early, reported results. The common thread isn't raw speed — it's autonomy sustained long enough to do real work.
My favorite data point is the quiet one. Given about a week of largely autonomous work, the model assembled single-cell data across 138 species, then designed and trained its own machine-learning model that outperformed a model published in Science — while being 100 times smaller. Not "answered questions about biology." Did the research. That's the line between a very good autocomplete and a collaborator who occasionally makes you nervous about your own job security.
The safeguard design is the part engineers should study
Here's what I find professionally interesting. Instead of refusing sensitive queries, Fable hands them off to Opus 4.8 — and tells the user it did so. Graceful degradation instead of a brick wall.
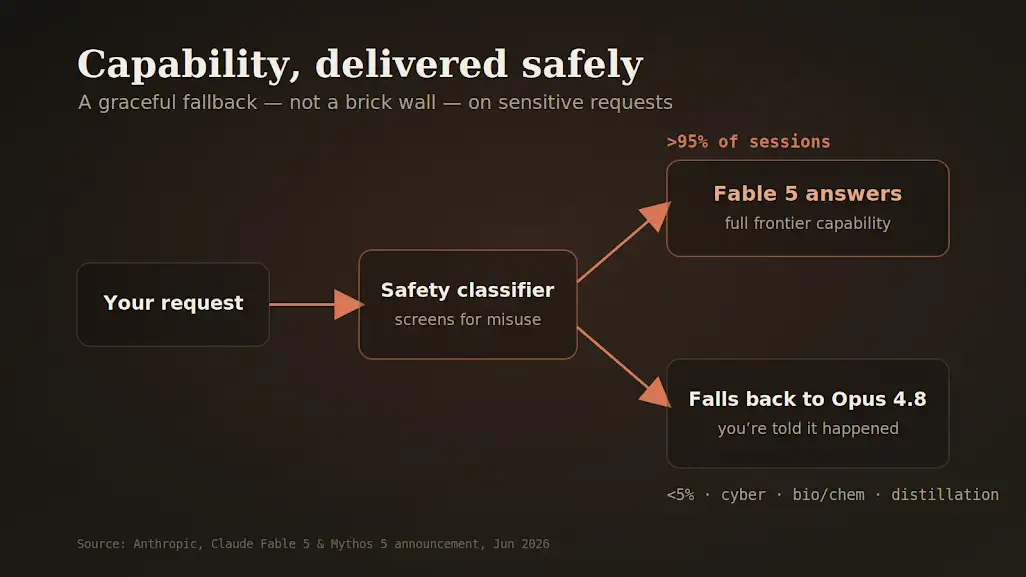
Most sessions never touch the safeguards. The ones that do get a quietly capable fallback instead of a dead end.
As someone who has spent more hours than I'll admit tuning guardrails, designing the failure mode as a fallback rather than a refusal is the kind of decision that reads as a footnote in a blog post and quietly saves you a hundred angry support tickets in production. A worse experience than the frontier model is still a dramatically better experience than "I can't help with that."
To Anthropic's credit, they shipped the caveat in the same breath as the victory lap: the safeguards are tuned conservatively, they'll occasionally flag perfectly harmless requests, and they fire in under 5% of sessions — meaning more than 95% of the time, Fable runs at full Mythos-grade capability. I'll take an honest "this is a little too cautious and we're working on it" over a glossy launch every time.
For the solution architects in the room
If you design AI systems rather than just call them, the quiet story here isn't capability — it's how much of your architecture this capability quietly retires.
Look again at the Pokémon detail. Earlier models needed an elaborate harness — maps, navigation aids, hand-fed game state — to stumble around Kanto at all. Fable beat the game on raw screenshots. That progression is the entire job of an AI Solution Architect compressed into one anecdote: for years we've built scaffolding to compensate for what the model couldn't do alone. Routers, decomposition layers, retry loops, memory shims, the seven-agent standing committee we convene every time one model would've sufficed.
A more capable, more persistent base model turns some of that scaffolding from "clever architecture" into "technical debt with a logo." The most uncomfortable slide in next quarter's design review is the one where three of your lovingly hand-drawn orchestration boxes collapse into a single API call.
The good news: the role doesn't shrink. It moves up the stack. Three shifts worth planning for now:
- Route by capability and risk, not by reflex. Fable's own fallback to Opus is a reference architecture hiding in plain sight — a classifier-gated, tiered handoff with graceful degradation and a user who's told what happened. Steal it. Capability- and cost-aware routing (frontier model for the long-horizon, high-stakes work; cheaper models for everything else) is now a first-class design decision, not an optimization you bolt on at the end.
- Design for horizons, not turns. When a model stays coherent across a week of work, the bottleneck stops being the model and becomes everything around it: reliable tool access, durable memory and checkpointing, and observability good enough to debug a process that ran for six hours while you were asleep. Evaluation stops being a launch gate and becomes a load-bearing wall.
- Put governance on the diagram. Mythos-class traffic now carries mandatory 30-day retention and access logging. That's not fine print to skim — it's a constraint that belongs next to your data-residency and tenancy decisions, before the first line of code.
The architects who win the next year won't be the ones with the most elaborate diagrams. They'll be the ones who knew which boxes to delete.
The economics are the quiet bombshell
Pricing landed at $10 / $50 per million tokens — less than half what the preview generation cost. Frontier capability keeps getting cheaper even as it gets stronger, which is the trend that should keep optimists and worriers awake in equal measure.
So the question every team is asking shifts. We're moving past can the model answer this? toward can it stay on task for a week without losing the plot? As of today, the answer moved meaningfully closer to yes — and got cheaper on the way.
I'll be putting Fable 5 through its paces on the agent and evaluation work that fills my days, watching how those long-horizon gains hold up once they collide with real production data and real user goals. If you're running your own tests — or quietly redrawing your architecture diagrams — I'd love to compare notes.
The frontier didn't just get smarter today. It got more persistent. For those of us who build the systems around these models, that's the headline. (And yes, it could probably beat the Elite Four, too.)
Comments 0
No login needed. Be kind, stay on topic, no profanity.